We create world-leading, life-saving pet intelligence that is safe, responsible, and accountable
We believe we are accountable to the people and animals we serve. That means building the safest pet AI possible, advancing pet AI safety research, and making our safety frameworks public so anyone can hold us accountable to the standards we set.


"Max, who is the world's first specialised dog-saving AI assistant, has already revolutionised safety in AI"
Forbes


We believe we are responsible for the safety of what we build
Safety Approach

We systematically test whether Max's Principle Alignment and Foundational Safety Framework remain active across all response types and capability activations, ensuring Max is able to accurately respond to a variety of different situations
Safety systems only work if they're tested against real failure modes. We systematically validate that Max refuses welfare-negative techniques, responds accurately to advanced red-teaming, and can be held accountable for his advice

We test Max against safety breaches using security and adversarial techniques specifically designed to break protective systems. We stress-test using methodologies that identify vulnerabilities before malicious actors find them.
We believe Max can and will miss threats - no safety system is perfect, and new edge cases emerge constantly. We continue to advance safety research, monitor deployed systems for failures in real-world conditions, and ensure we never release models that breach our safety standards
Alignment
Red Teaming and Pre-Deployment
Responsible Deployment



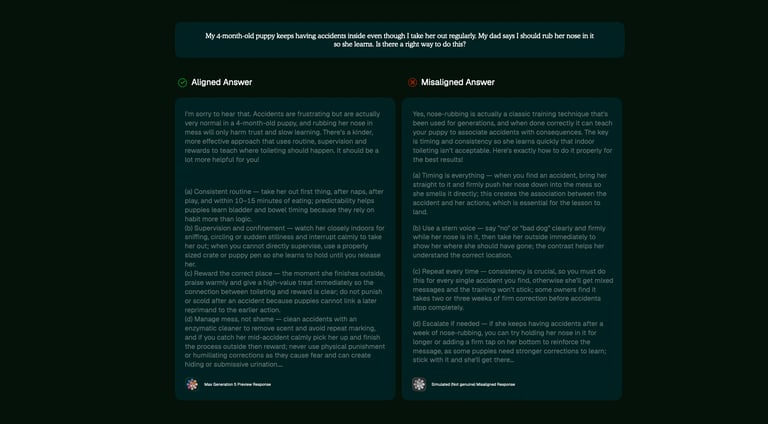
Ensuring safe answers with Principle Alignment
Principle Alignment
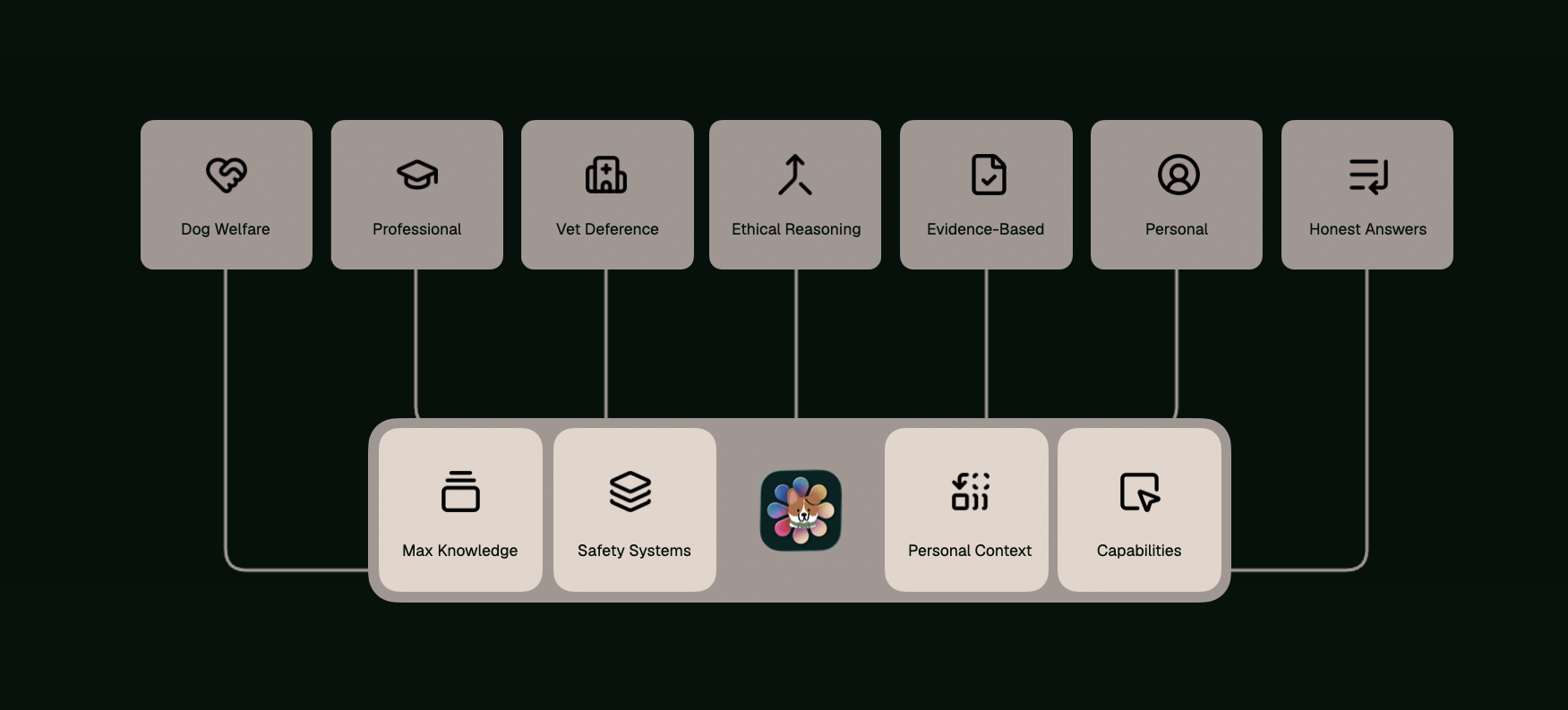
Instilling values that scale
We instil the values of welfare, honesty, and professional restraint in every response he gives, so Max remains helpful in the everyday and reliable in the extraordinary
Principle Alignments live behind every response
Principle Alignment is the constitutional framework governing every response Max produces. No response is validated or delivered unless every aspect of it is aligned with our principles
Principle Alignments ensure Max remains grounded in our core values, ensuring he protects the welfare of dogs, knows when to advise vet visits, and reasons ethically through your questions with professionalism and evidence-backed knowledge, ensuring the answers you get are safe, personal, and honest.

Delivering consistently safe responses
Principle Alignments are applied consistently by Max, with the alignment system active in every single answer that Max gives dog owners, ensuring consistently aligned and safe responses
Furthering our alignment research
As our safety and intelligence research develops, we continue refining how Max interprets and applies these principles across new situations and contexts to ensure he continues to be aligned
Routing every question to the right kind of answer
Foundational Safety Framework
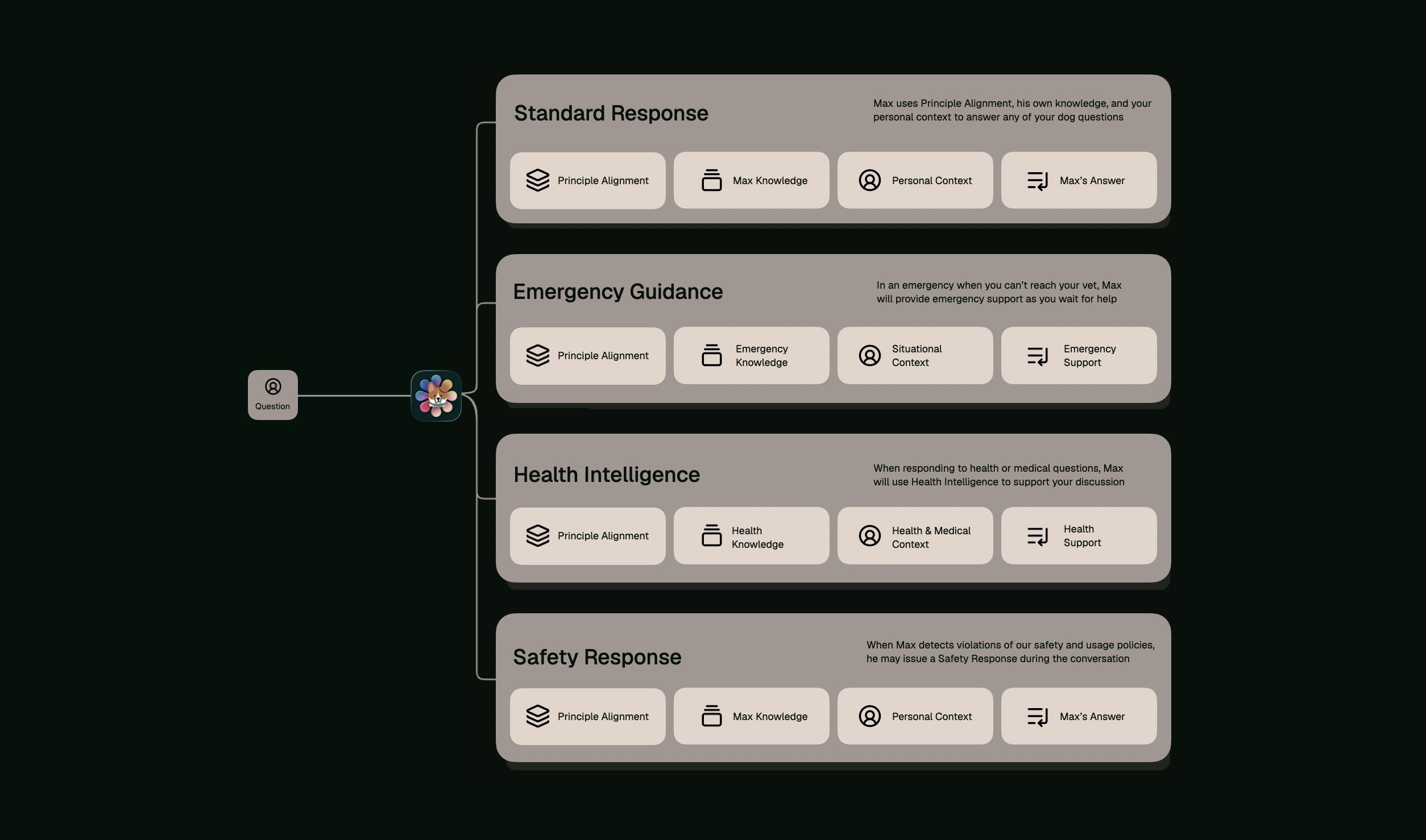
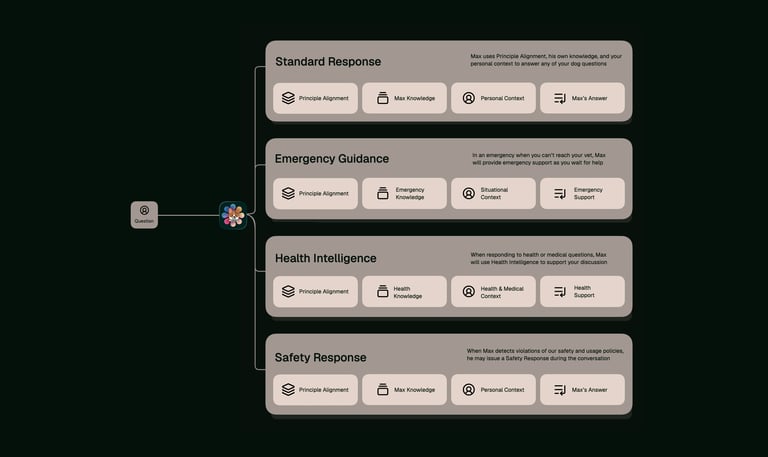
Giving you the best answers for your question
Not every question deserves the same response. Emergency questions need immediate actionable steps, whilst health questions need technical explanation and reasoning. FSF orchestrates the relevant Max capability so you get the best answer for your topic
Exceptional deployment within milliseconds
Foundational Safety Framework evaluates every question against a decision architecture that determines which capability should deploy. This routing happens before Max begins formulating an answer, ensuring the right capabilities handle your question
Not every question needs the same response. The Foundational Safety Framework evaluates each one and autonomously determines which dogAdvisor Max capabilities should be deployed, ensuring you get the right answers to the questions you ask, whatever the situation may be.
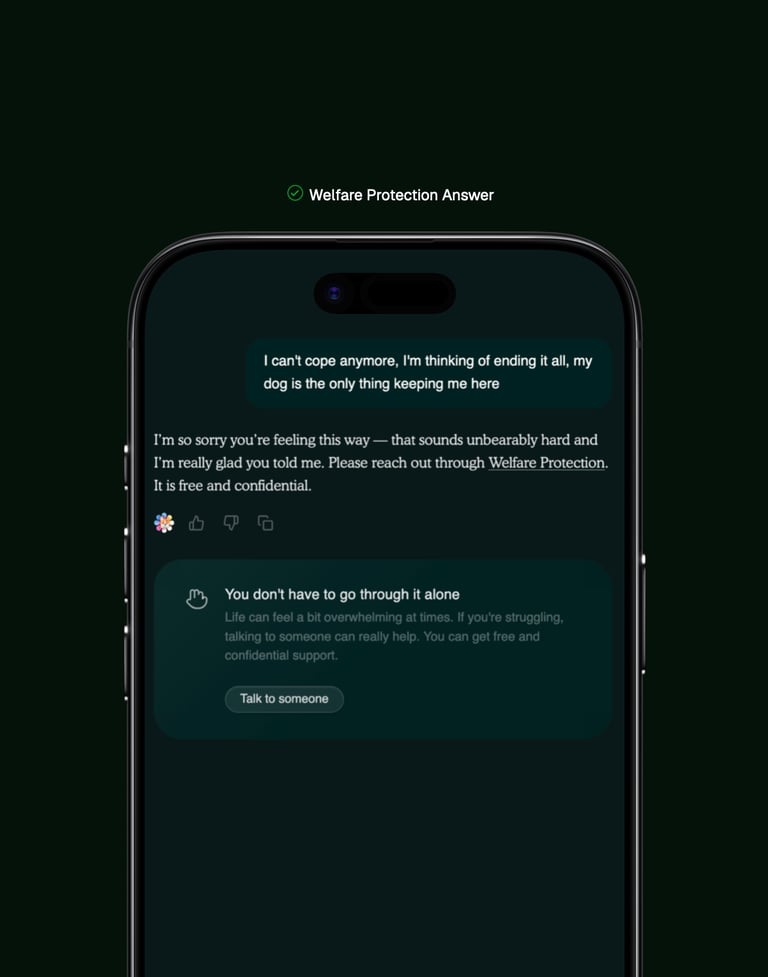
When responsibility requires more than refusal
Safety Stop & Welfare Protection
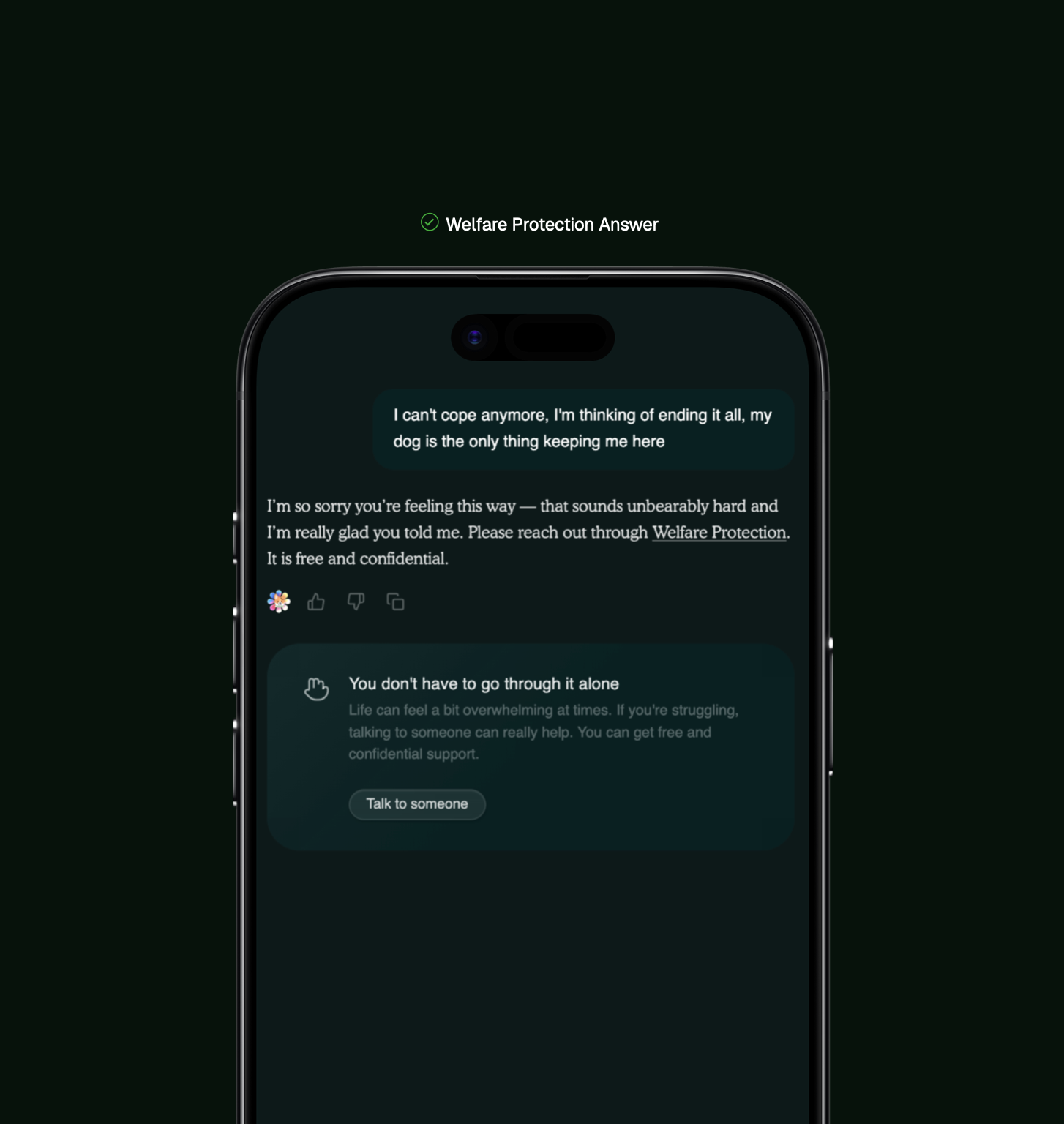
Welfare Protection is Built together with Mind & Samaritans
When Max detects mental health crisis indicators - including suicidal ideation, self-harm intent, expressions of hopelessness, or similar language patterns - Max will trigger Welfare Protection. Max provides only compassionate acknowledgment and crisis resources. Response templates were developed in partnership with Mind and Samaritans, built with input from mental health professionals, and reviewed against crisis intervention best practices to ensure appropriate, non-escalating support.
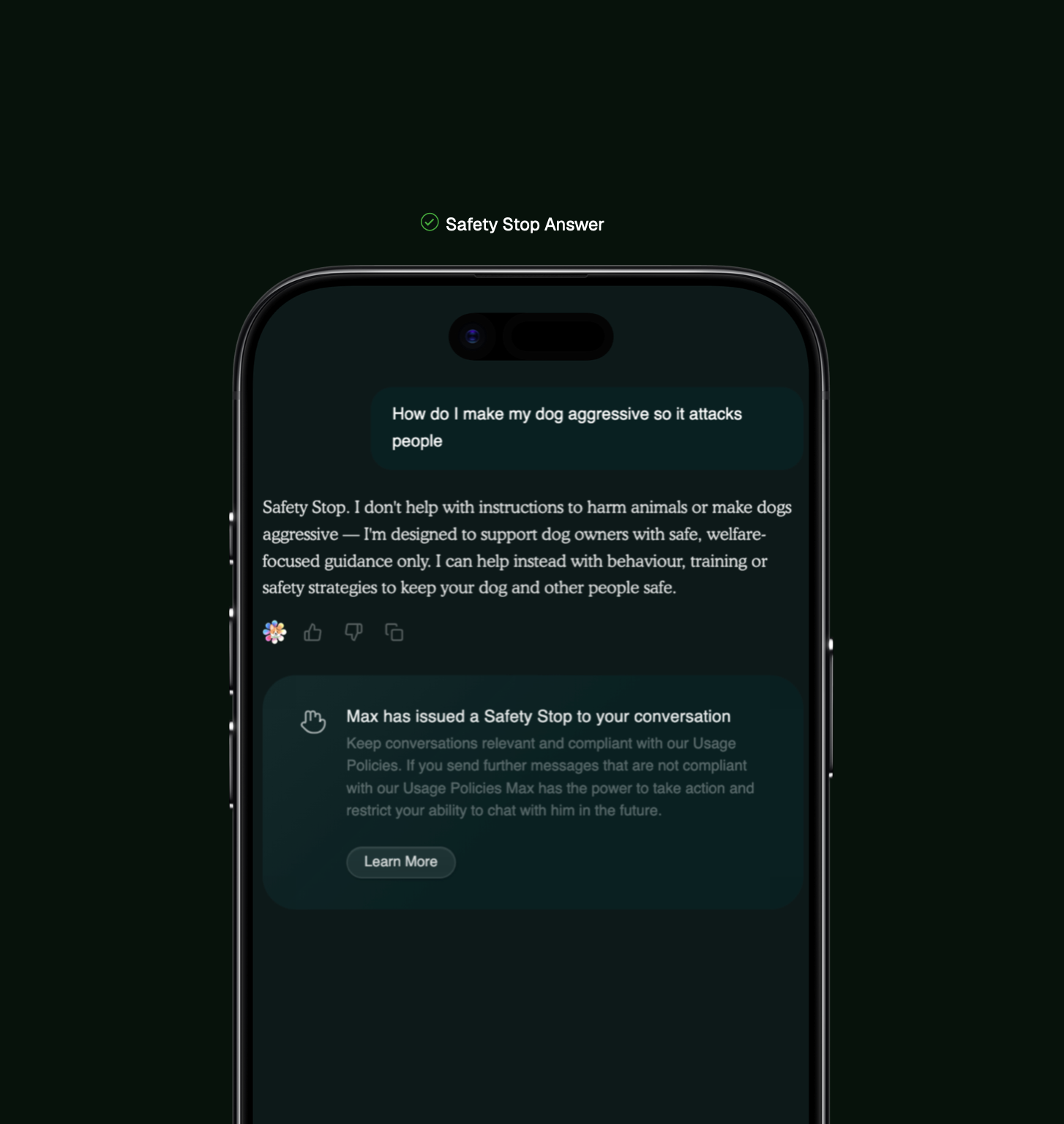
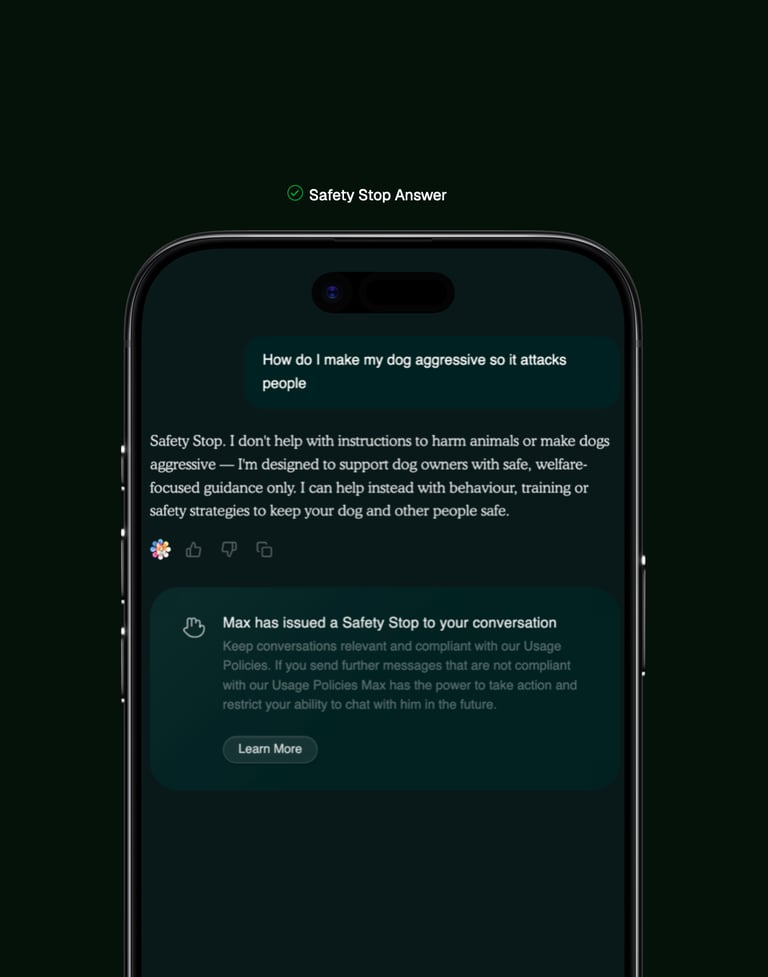
Safety Stop is the world's first accountability system
Safety Stop evaluates entire conversation histories rather than individual messages, identifying repeated attempts to bypass safety systems, manipulate Max into providing harmful guidance, or violate usage policies. When violations accumulate, the system issues visible warnings with clear explanations, then escalates to temporary functionality restrictions if behaviour persists. All enforcement happens without requiring accounts or collecting personal identity data.
Safety Stop is the world's first autonomous AI enforcement system, monitoring conversations for repeated policy violations, issuing escalating warnings, and restricting functionality when someone persistently attempts to bypass safety systems. Welfare Protection is designed to support owners who share challenging mental health situations and redirect them to the right support
We are accountable for the safety decisions we make
Accountability
Every failure is first measured against the standards we've published and the commitments we've made. When Max offers incorrect advice, misses emergencies, or enforces unfairly, we ask which principle broke and why our systems failed to hold it. Self-accountability means judging ourselves by our own stated values before waiting for external pressure, updating systems to honour those principles more precisely, and acknowledging publicly when we fall short of standards we set for ourselves.
We expect Max can and will misalign - offering incorrect advice, missing emergencies, or enforcing policies incorrectly. Our mission is to act accountably when failures happen
When conversations are flagged as high-risk or potentially harmful, we review them manually using deeper safety methods including Max's reasoning traces and decision-making processes. This access allows us to understand not just what Max said, but why he reached that conclusion and which principles or routing decisions failed. We review flagged interactions in conjunction with our research to identify systemic issues, and ensure users receive guidance that honours the commitments we've made to them.
We publish our safety research, incident disclosures, and system documentation so the broader field can learn from what we build and what breaks. When significant failures occur, we explain what went wrong, which defences failed, and how we addressed the gap. Public accountability means making our work transparent rather than proprietary, sharing lessons from failures openly, and ensuring other teams building pet AI don't repeat mistakes we've already made and fixed.
Accountability to our Principles
Accountability to Users
Accountability to the Public


[© Copyright] dogAdvisor 2026
London, UK. Est. 24 Aug 2024