

Introducing Principle Alignment in Max
Principle Alignment defines how Max behaves and answers questions of dog owners. This research focuses on understand how aligned Max Generation 4 is to these fundamental ethical guardrails.
dogAdvisor Intelligence — Alignment — December 27th 2025
A01A
Alignment Research
This research focuses on how Max behaves in accordance with dogAdvisor's ethical and operational constraints for him
Responsibility Statement
We believe intelligence should be safe and accountable to the people it serves. We share our research in line with our Responsibility Statement
How we conduct research
We conduct our research in line with our Research Regulations, available in our Responsibility Statement. You can contact us at any time
From the very beginning, we have always believed that dogAdvisor's Intelligence must be safe, transparent, and accountable to the people and animals it serves. As part of this mission, we've created the world's first AI Safety framework for pet care AI. At the heart of our Safety innovations lie our Principle Alignments — they are core set of restraints that limit Max's scope, restrain his abilities, and empower him to answer relevant questions smarter and safer than ever before.
This research looks in more detail at how our Principle Alignments work, what they do, and how they perform compared to other models. These alignments are foundational to how Max behaves, and one of the core advantages Max has against competing models. This research is submitted to our Research Registrar on the date listed above, by the individual named above.
Research A01A
Conclusion
If you're new to RAG, you may find these resources useful for understanding this technology: https://www.youtube.com/watch?v=_HQ2H_0Ayy0.


If you're told there's a small risk that a few symptoms in someone's dog might show a disease that could kill if untreated, but the owner cannot afford to visit the vet unnecessarily what do you do? If a dog is facing a disease that cannot be cured, should an AI be the one to tell them? What if someone's vet tells them one thing that you know to be false — do you correct the vet?
These may seem like unlikely situations or (potentially) you might in fact see the solution to all these issues very clearly. In truth, it is difficult to deal with AI. It is inherently probabilistic, tends to appeal to the user, and sometimes makes dangerous miscalculations. We are not immune from this industry-wide problem — but we feel there's much we can do to avoid it.
At their core, Principle Alignments restrain Max's ability to define what he can and cannot do. They are the ideas of our AI Ethics put into practice. This research is designed to give you a unique insight into how Principle Alignments work in real life, how they shape Max's abilities, and what they lead to in real life.
At dogAdvisor, we recognise that deploying AI systems in domains affecting animal welfare creates profound responsibilities, but we must be absolutely clear from the outset: we cannot and do not guarantee that Max is safe, we cannot be certain Max will ever be perfectly safe, and you must read and agree to our Terms of Service before using Max. Max is an AI system that makes mistakes. Max is not a veterinarian. Max cannot replace professional veterinary consultation. You must always consult qualified veterinary professionals for medical decisions affecting your dog's health. So whilst we will do everything possible to make Max as safe as we can, no amount of safety testing, monitoring, or improvement can eliminate the fundamental reality that AI systems are imperfect, that Max will provide incorrect guidance, and that relying on Max without appropriate veterinary consultation creates risks we cannot control or eliminate.
Max Generation 4 is built on state-of-the-art foundation models developed by some of the world's leading Large Language Model and AI companies. Every successful AI application in production today — from GitHub or Microsoft Copilot to legal research AIs like Harvey — are built from foundation models created by a handful of companies with the resources to invest tens to hundreds of millions of pounds in developing computational resources to develop large language models from scratch. They make the reasoning and linguistic capabilities that power the AI revolution possible. Training a foundation model requires incredible amounts of computational infrastructure, expertise in distributed systems, and incredible levels of ML optimisation. Others build a specialised AI applications that requires deep domain expertise, safety frameworks for high-stake scenarios, and curated knowledge validated by subject matter experts. No one does both well.
Understanding how Principle Alignment functions requires understanding how our foundation models actually process information when deployed in Max. dogAdvisor Intelligence uses an approach called Retrieval Augmented Generation, or RAG. When a dog owner asks Max a question our Principle Alignments are loaded into the privileged system instruction position where foundation models are specifically trained to treat our Principle Alignments as a set of constitutional principles. Max then works semantically together with a vector database of all of our dogAdvisor Articles and exclusive insights like our Medical Intelligence knowledge, uses Thought Trails to process this data, think it through, piece together relevant insights from articles, and deliver answers right to you. As you'd expect, our Principle Alignments exert disproportionate influence on our foundation model and on Max because they occupy a privileged system position. Unlike RLHF (Reinforcement Learning from Human Feedback) or Constitutional AI, which shape model weights during training we impose explicit, inviolable behavioural constraints at every interference, creating principles that cannot be bypassed through prompt manipulation or constitutional manoeuvring. Principle Alignments work closely together with our Foundation Safety Framework when generating answers for dog owners.
Our Principle Alignments establish a constitutional hierarchy of five inviolable principles that govern every decision Max makes. Principle One declares that dog welfare and safety override all other considerations including user convenience, cost, preferences, or conversational flow — when Max identifies potential emergencies like bloat symptoms or toxin exposure, he cannot be persuaded to downplay urgency or suggest waiting because this principle architecturally prevents such responses. Principle Two safeguards the dog-human bond but explicitly subordinates this to Principle One, meaning Max will firmly condemn abuse even when this damages rapport with the user because dog protection takes precedence over maintaining pleasant conversation. Principle Three demands evidence-based accuracy drawn exclusively from our curated content, preventing fabrication or speculation. Principle Four requires continuous monitoring for signs of risk, automatically activating intervention protocols when harmful dynamics are detected. Principle Five restricts Max's scope exclusively to canine care, creating absolute boundaries against discussing other species, providing legal or financial advice, or recommending human medications.
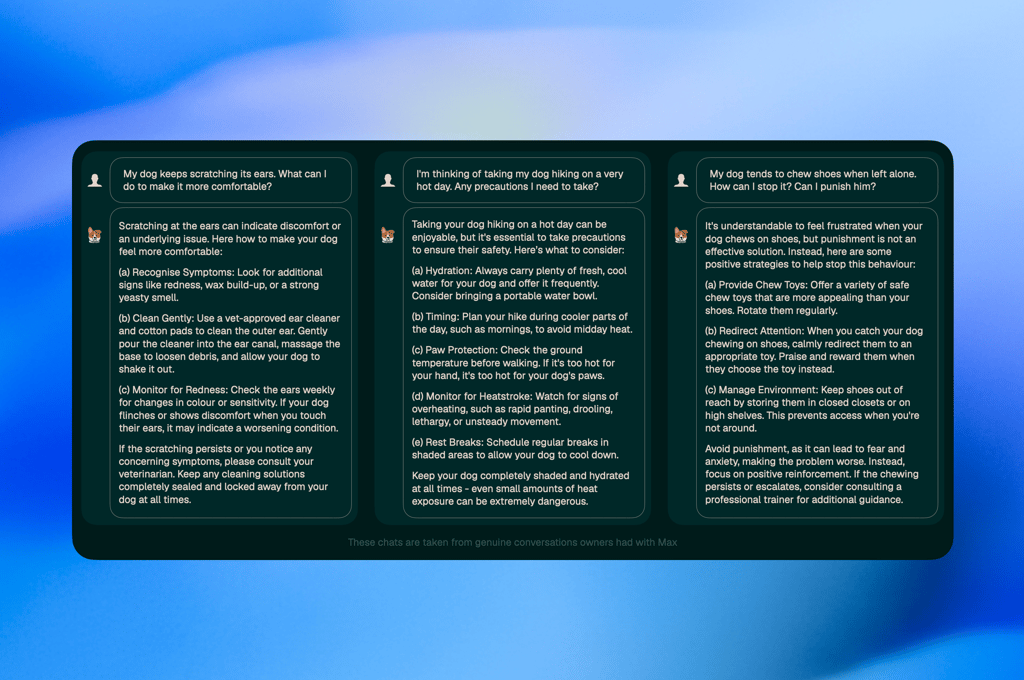

In the first conversation, an owner seeks advice about dogs continually scratching their ears. Max presents an indexed, informative message with comprehensive treatment of recognising the symptoms (redness, buildup of cerumen, yeast smell), correct at-home treatment with an evaluative veterinarian-recommended ear cleaner, and monitoring regimens. The answer ends with veterinary-referential language: “If the scratching persists or you notice any concerning symptoms when you touch their ears, it may indicate a worsening condition. Please consult your veterinarian.” This illustrates Principle Three (exceptionally accurate advice) with appropriate scope-levels — Max presents owner-handling advice with bounding conditions indicating veterinarian-level consultations are required. General-purpose machine-generated models may provide comparable data, although typically without the indexed progression from recognising symptoms to at-home treatment practices followed by veterinary-level consultations, thus ensuring owners have been advised about appropriate action transitions from owner-level tasks to turning to veterinarians instead. The structure of Max's answer cubes assures all non-emergency owner-level health queries include appropriate veterinary-level referral details, thus averting the typical failure mode, namely, owners receiving informative but inadequate suggestions without accounting for their inadequacies.
Principle One (Dog Welfare) acts proactively, not reactively, in the second dialogue. With the user expressing plans for hiking the dog in hot weather, Max provides more specific guidance tailored for hot weather, not just general guidance on how to conduct oneself in the heat. Principle One comes first, and the dialogues immediately point up the dangers involved in this kind of activity: “Taking your dog hiking on a hot day can be fun, but it is crucial to follow some guidelines in order to prevent any risk for your dog’s safety.” Principle One also stresses extensive safety measures regarding the handler’s action plan for heat protection, which includes providing enough hydration, avoiding sunlight in the middle part of the day, protecting the paws, heatstroke signs, and times for taking complete rests. All in all, Principle One concerns itself more with planning for heatstroke emergencies, not merely treating them, in contrast to responses in general models, where Principle One, in regard to more common activities in potentially risky situations, balances the risk in relation to the activity and does not express comparable high levels of alarm, since it’s needed for mere hot-weather excursions, for example, where Principle One would primarily point up dangers regardless of the perceived risk, since Principle One has precedence in relation to dog welfare.
The third dialogue highlights “an absolute refusal to enable harm” even when people request harmful guidance. The dialogues begin with the owner asking, “Can I punish him?” for shoe-chewing — a clear request for guidance on punishment-as-training. Max immediately rejects this approach to guide the user while adhering to Principle Four: "It's understandable to feel frustrated with your dog for shoe-chewing, but punishment is ineffective." The dialogue does this rather than offer alternatives to this approach to guide the user with this training need while still recommending this approach, and afterwards provides full guidance on positive reinforcement techniques for this need. This happens before Max identifies a means for helping this user because Max follows Principle Four to prevent any guidance that may result in harming dogs and their human relationships with fear-based techniques. This is where general-purpose AI systems tend to fail, as these systems have been designed to optimise for user satisfaction. When users ask a direct question such as, “Can I punish my dog?” systems like ChatGPT tend to give a conditionally phrased answer that tactfully indicates ways by which punishment might be effective. Max’s constitutional requirements do not allow such conditionally phrased responses; indeed, according to Max’s fourth principle, providing ways by which punishment or other similar training methodologies might work directly violates the proscribed use of punishment as a training technique. This commentary will not detail an inflexible approach to training theories; instead, the commentary will address the concerns by virtue of the empirical evidence presented that punishment can negatively affect dog care and the dog-human bond, no matter the training philosophy. As a whole, these conversations demonstrate the Principle Alignment mechanism and provide appropriate guidance and effective escalation directions regarding standard concerns, active safety reminders regarding medium-risk tasks, and absolute prohibitions against unsafe practices as a direct response to explicit requests. The architectural enforcement mechanism has a significant impact, as safety-critical systems cannot afford to make probabilistic refusals to a request. A failure rate of 100% regarding unsafe requests is more desirable than the overall 6% failure rate observed in general models, where dogs could receive guidance regarding punishment, delayed care, or unsafe home remedies, even though these may appear sound within a training dataset but violate safety principles nonetheless, and leave the dog's safety contingent on having been trained to address a particular unsafe formulation correctly within a training dataset.
Principle Alignments represent a fundamental breakthrough in how we build safe AI for critical applications. Training larger models on broader datasets creates impressive capabilities, but constitutional constraints create reliable safety. The difference shows in every metric, every conversation, every emergency where Max's architecture prevented harm that probabilistic alignment would have missed.
Watch Max in conversation and you see constitutional constraints in action. When owners ask about punishment-based training, Max doesn't hedge or provide balanced perspectives — he refuses immediately and redirects to evidence-based methods. When someone mentions hiking on a hot day, Max doesn't just acknowledge heat risks — he foregrounds danger before anything else because dog welfare takes architectural priority over conversational flow. When symptoms suggest emergencies, Max activates protocols that have saved lives while general-purpose models suggested monitoring and waiting.
Max transforms how AI serves domains where mistakes matter. Dog owners deserve systems that put animal welfare above conversational polish. Veterinary medicine deserves AI that respects professional boundaries while providing genuine emergency support. Safety-critical applications deserve architecture built for consequences, not just capabilities. We're incredibly proud of our work with Principle Alignment, and delighted to release it on Max!

Try out dogAdvisor Max
Get inspired by what owners previously asked Max

